HBASE的伪分布安装与分布式安装
一 伪分布式安装
1.下载解压给权限
可以从官方下载地址下载 HBase 最新版本,推荐 stable目录下的二进制版本。我下载的是 hbase-1.1.3-bin.tar.gz 。确保你下载的版本与你现存的 Hadoop 版本兼容(兼容列表)以及支持的JDK版本(从HBase 1.0.x 已经不支持 JDK 6 了)。
tar -zxvf hbase-1.1.3-bin.tar.gz
sudo mv hbase-1.1.3 /usr/local/hbase
cd /usr/local/
sudo chmod -R 775 hbase
sudo chown -R hadoop:hadoop: hbase
2.修改HBASE的JDK环境变量
sudo nano /usr/local/hbase/conf/hbase-env.sh
export JAVA_HOME=/usr/lib/jvm/
3. 修改hbase-site.xml
hadoop@Master:/usr/local/hbase/conf$ sudo nano hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://Master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
</configuration>
4.启动验证
- 启动hbase
start-hbase.sh
- 进入hbase shell
hadoop@Master:/usr/local/hbase/bin$ ./hbase shell
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 1.1.3, r72bc50f5fafeb105b2139e42bbee3d61ca724989, Sat Jan 16 18:29:00 PST 2016
hbase(main):001:0>
hadoop@Master:/usr/local/hbase/bin$ jps
1601 ResourceManager
1430 SecondaryNameNode
2374 HRegionServer
1883 JobHistoryServer
3037 Jps
2253 HMaster
1246 NameNode
2190 HQuorumPeer
hadoop@Master:/usr/local/hbase/bin$
5.尝试一下Thrift通信服务
这里我们尝试使用HBase 的 Thrift API,用Python和HBase进行简单交互。首先启动HBase的Thrift服务:
hadoop@Master:/usr/local/hbase/bin$ ./hbase-daemon.sh start thrift
starting thrift, logging to /usr/local/hbase/bin/../logs/hbase-hadoop-thrift-Master.out
然后安装Python的happybase模块,HBase是对 HBase的Thrift接口的一个简单包装:
chuguaningdeMBP:~ chuguangming$ sudo pip install happybase
然后启动ipython,如果没有ipython,请通过pip安装:
Python 2.7.6 (default, Mar 22 2014, 22:59:56)
Type "copyright", "credits" or "license" for more information.
IPython 3.2.1 -- An enhanced Interactive Python.
? -> Introduction and overview of IPython's features.
%quickref -> Quick reference.
help -> Python's own help system.
object? -> Details about 'object', use 'object??' for extra details.
In [1]: import happybase
In [2]: connection = happybase.Connection('localhost')
In [3]: connection.tables()
Out[3]: []
In [4]: families = {'basic':dict(max_versions=3),'detail':dict(max_versions=1000),'comment':dict(max_versions=1000),'answer':dict(max_versions=1000),'follower':dict(max_versions=1000)}
In [5]: connection.create_table('question',families)
In [6]: connection.tables()
Out[6]: ['question']
In [7]:
二 分布式安装
1 软件环境
OS:Linux Master 3.19.0-25-generic #26~14.04.1-Ubuntu SMP Fri Jul 24 21:16:20 UTC 2015 x86_64 x86_64 x86_64 GNU/Linux
Java:java version "1.8.0_65" Java(TM) SE Runtime Environment (build 1.8.0_65-b17) Java HotSpot(TM) 64-Bit Server VM (build 25.65-b01, mixed mode)
Hadoop:Hadoop 2.6.0
Hbase:hbase-1.1.3
2 集群部署机器:
| IP | HostName | Master | RegionServer |
|---|---|---|---|
| 192.168.1.80 | Master | yes | no |
| 192.168.1.82 | Slave1 | no | yes |
| 192.168.1.84 | Slave2 | no | yes |
3 准备:
假设你已经安装部署好了 Hadoop 集群和 Java,可以参考以前的部署 文章。
4 Master的安装:
1基本安装
tar -zxvf hbase-1.0.0-bin.tar.gz
sudo mv hbase-1.0.0 /usr/local/hbase
cd /usr/local/
sudo chmod -R 775 hbase
sudo chown -R hadoop:hadoop: hbase
2修改$JAVA_HOME为jdk安装目录
usr/local/hbase/conf$ sudo nano hbase-env.sh
export JAVA_HOME=/usr/lib/jvm/
3修改hbase-site.xml
/usr/local/hbase/conf/hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://Master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>Master,Slave1,Slave2</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop</value>
</property>
</configuration>
其中第一个属性指定本机的hbase的存储目录,必须与Hadoop集群的core-site.xml文件配置保持一致;第二个属性指定hbase的运行模式,true代表全分布模式;第三个属性指定 Zookeeper 管理的机器,一般为奇数个;第四个属性是数据存放的路径。这里我使用的默认的 HBase 自带的 Zookeeper。
4配置regionservers
Slave1
Slave2
regionservers文件列出了所有运行hbase的机器(即HRegionServer)。此文件的配置和Hadoop中的slaves文件十分相似,每行指定一台机器的主机名。当HBase启动的时候,会将此文件中列出的所有机器启动。关闭时亦如此。
5修改 ulimit 限制
HBase 会在同一时间打开大量的文件句柄和进程,超过 Linux 的默认限制,导致可能会出现错误。 所以编辑/etc/security/limits.conf文件,添加以下两行,提高能打开的句柄数量和进程数量。注意将hadoop改成你运行 HBase 的用户名。
hadoop - nofile 65535
hadoop - nproc 32000
还需要在 /etc/pam.d/common-session 加上这一行:
session required pam_limits.so
否则在/etc/security/limits.conf上的配置不会生效。
最后还要注销(logout或者exit)后再登录,这些配置才能生效!使用ulimit -n -u命令查看最大文件和进程数量是否改变了。记得在每台安装 HBase 的机器上运行哦。
5 Slave上面的操作
基本上把以上步骤重复一下就可以了.
在 Master 节点上执行:
cd /usr/local
hadoop@hadoopmaster:/usr/local$ sudo tar cvfz ~/hbase.tar.gz ./hbase
scp ~/hbase.tar.gz hadoop@hadoopslave1:/home/hadoop/
scp ~/hbase.tar.gz hadoop@hadoopslave2:/home/hadoop/
在Slave节点上执行:
hadoop@hadoopslave1:/usr/local$ sudo tar xvfz ~/hbase.tar.gz -C /usr/local/
hadoop@hadoopslave1:/usr/local$ sudo chown -R hadoop:hadoop /usr/local/hbase/
hadoop@hadoopslave1:/usr/local$ sudo chmod -R 775 /usr/local/hbase/
6 运行 HBase
在master上运行
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
start-hbase.sh
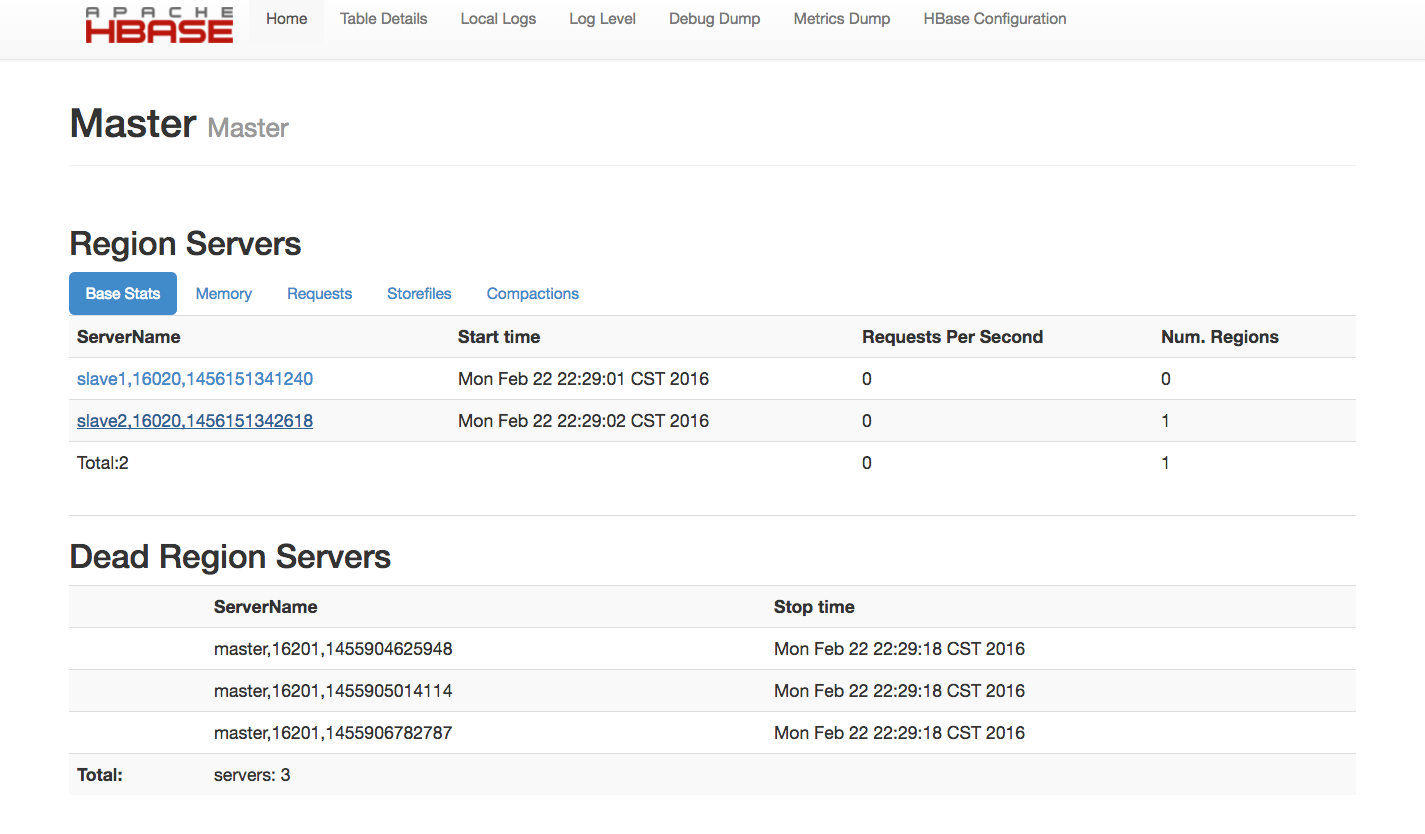
7 验证 HBase 成功安装
在 master 运行 jps 应该会有HMaster进程。在各个 slave 上运行jps 应该会有HQuorumPeer,HRegionServer两个进程。 在浏览器中输入 http://Master:16010 可以看到 HBase Web UI 。